개인 기록용
-------------------
학습에 참고한 사이트 : learncpp.com
학습한 챕터 : 챕터 4
학습에 참고한 번역 프롬프트 : 해당 원문은 learncpp.com에서 발췌해온 c++ 강의 내용인데, 프로그래밍 용어는 한국어 표준 용어를 사용하되, 이해를 돕기 위해 필요한 경우 원문을 병기해서 한국어로 번역해줘.
-------------------
자료형 (Data types)
• 객체에 값을 부여하면, 컴파일러와 CPU는 여러분이 입력한 값을 해당 자료형에 맞는 적절한 비트 순서로 인코딩하여 메모리에 저장합니다(기억하세요: 메모리는 비트만 저장할 수 있습니다).
• 예를 들어, 정수형 객체에 값 65를 할당하면, 이 값은 비트열 0100 0001로 변환되어 해당 객체에 할당된 메모리에 저장됩니다.
• 반대로, 객체가 평가되어 값을 생성할 때는, 해당 비트열이 다시 원래의 값으로 복원됩니다. 즉, 0100 0001은 다시 값 65로 변환됩니다.
• 다행히도 컴파일러와 CPU가 이러한 어려운 작업을 모두 처리해주므로, 일반적으로 값이 어떻게 비트열로 변환되고 다시 돌아오는지 걱정할 필요는 없습니다.
다양한 종류의 자료형 (Other sets of types)
• C++에는 세 가지 종류의 자료형이 있습니다.
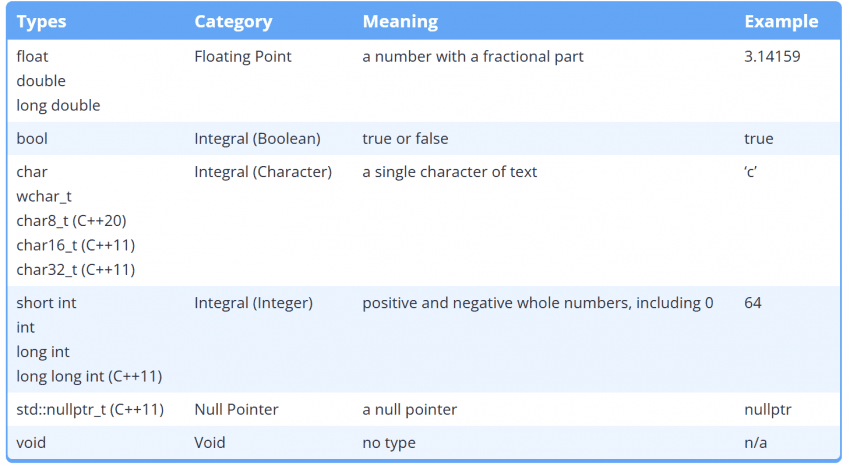
• 기본 자료형(fundamental data types): 가장 기초적이고 필수적인 자료형을 제공합니다 .C++ 언어에 내장(built-in) 된 가장 기본 자료형들.
• 기본 자료형: int, double, char, bool …
• 복합 자료형(compound data types): 기본 자료형을 조합해서 만들거나, “형태”가 더 복잡한 타입들. (C++ 언어 차원에서 제공)
• 복합 자료형: int*, int&, int+, struct Point, enum Color …
• C++ 표준 라이브러리 자료형(C++ standard library): 표준 라이브러리는 모든 C++ 배포판에 포함되어 있으므로, 이 타입들은 광범위하게 사용 가능하며 호환성을 위해 표준화되어 있습니다. 표준 라이브러리의 타입을 사용하려면 적절한 헤더를 포함(include)하고 표준 라이브러리를 링크해야 합니다.
• 표준 라이브러리 타입: std::string, std::vector<int>, std::map<...>, std::unique_ptr<...> …
기본 자료형 (Fundamental data types)
• C++ 언어는 사용자가 바로 사용할 수 있는 많은 미리 정의된 자료형을 제공합니다.
• 이 중 가장 기본적인 것들을 기본 자료형(fundamental data types)이라고 합니다.
• 비공식적으로는 기초 타입(basic types) 또는 원시 타입(primitive types)이라고도 부릅니다).
정수(Integer) vs 정수형(Integral) 타입
• 표준 정수 타입(standard integer types): short, int, long, long long (각각의 signed 및 unsigned 변형 포함).
• 정수형 타입(integral types): bool, 다양한 char 타입들, 그리고 표준 정수 타입들.
• 모든 정수형(integral) 타입은 메모리에 정수 값으로 저장되지만, 출력 시 표준 정수(integer) 타입만이 정수 값(숫자)으로 표시됩니다.
• 또한 "정수형 타입"이라는 용어는 오직 기본 자료형만을 포함한다는 점에 유의하세요. 이는 enum이나 enum class 같은 비(非)기본 자료형은 정수형 타입이 아니라는 것을 의미합니다(비록 정수로 저장되고, enum의 경우 정수로 출력되더라도 말이죠).
_t 접미사 (The _t suffix)
• 새로운 버전의 C++에서 정의된 많은 타입들(예: std::nullptr_t)은 _t 접미사를 사용합니다.
• 이 접미사는 "타입(type)"을 의미하며, 현대적인 타입들에 적용되는 일반적인 명칭법입니다.
• 만약 _t가 붙은 무언가를 본다면, 그것은 아마도 타입일 것입니다. 하지만 많은 타입들이 _t 접미사를 가지고 있지 않으므로, 이것이 일관되게 적용되는 규칙은 아닙니다.
보이드 (Void)
• 기본적으로 void는 "타입 없음(no type)"을 의미합니다.
• 보이드는 불완전한 타입(incomplete type)의 첫 번째 예시입니다.
• 불완전한 타입이란 선언은 되었으나 아직 정의되지 않은 타입을 말합니다.
• 불완전한 타입은 인스턴스화(instantiated)할 수 없습니다
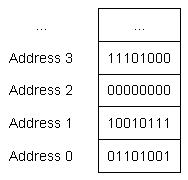
객체 크기 (Object sizes)
• 최신 컴퓨터의 메모리는 보통 바이트(byte) 단위로 구성됩니다.
• 각 메모리 바이트는 고유한 주소(address)를 가지고 있습니다.
• 객체가 사용하는 메모리의 양은 해당 객체의 자료형(data type)에 따라 결정됩니다.
기본 자료형 크기 (Fundamental data type sizes)
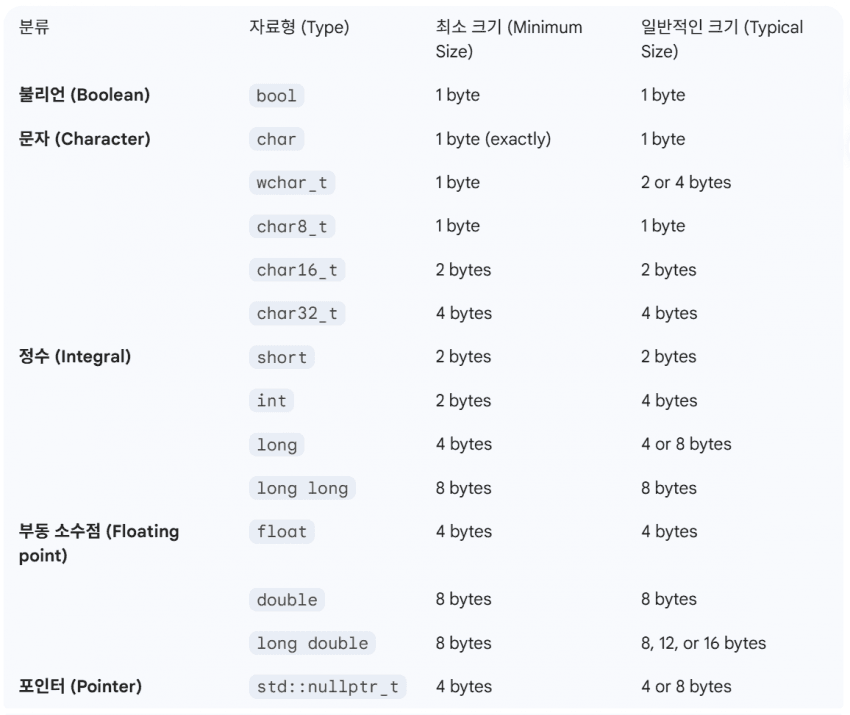
• 놀랍게도 C++ 표준(standard)은 기본 자료형(fundamental types)의 정확한 크기(비트 단위)를 정의하지 않습니다.
• 자료형의 크기를 말할 때는, 실제로는 해당 자료형으로 인스턴스화된(instantiated) 객체의 크기를 의미합니다.
• 대신 표준은 다음과 같이 명시합니다:
• 객체는 최소 1바이트를 차지해야 합니다 (각 객체가 고유한 메모리 주소를 갖도록 하기 위함).
• 1바이트는 최소 8비트여야 합니다.
• 정수형인 char, short, int, long, long long은 각각 최소 8, 16, 16, 32, 64비트의 크기를 가집니다.
• char와 char8_t는 정확히 1바이트입니다 (최소 8비트).
sizeof 연산자 (The sizeof operator)
• 특정 머신에서 자료형의 크기를 확인하기 위해, C++은 sizeof라는 연산자를 제공합니다.
• sizeof 연산자는 자료형이나 변수를 받아 해당 자료형의 객체 크기를 바이트 단위로 반환하는 단항 연산자(unary operator)입니다.
오버플로우 (Overflow)
• 표현식 평가 중 결과가 수학적으로 정의되지 않거나 해당 타입의 표현 가능한 값 범위에 있지 않은 경우, 그 동작은 미정의(undefined)됩니다.
• 통상적으로 이를 오버플로우(overflow)라고 부릅니다.
• 산술 연산(덧셈이나 곱셈 등)이 표현 가능한 범위를 벗어나는 값을 생성하려고 시도하는 것을 정수 오버플로우(integer overflow) 또는 산술 오버플로우(arithmetic overflow)라고 합니다.
부호 없는 정수의 오버플로우 (Overflow)
• 숫자 280은 1바이트 범위인 0~255에 담기에 너무 큽니다.
• 이 타입의 가장 큰 수보다 1 큰 수는 256입니다.
• 따라서 280을 256으로 나누면 몫은 1이고 나머지는 24가 됩니다.
• 결과적으로 24가 저장됩니다.
• 이를 생각하는 또 다른 방법은 모듈러 래핑(modulo wrapping) 또는 순환(wrap around)입니다.
• 해당 타입으로 표현할 수 있는 가장 큰 수보다 큰 수는 단순히 범위를 "한 바퀴 돌아서" 처음으로 돌아갑니다.
• 255는 1바이트 정수 범위 내에 있으므로 괜찮습니다.
• 하지만 256은 범위를 벗어나므로, 한 바퀴 돌아 값 0이 됩니다.
• 257은 값 1이 됩니다. 280은 값 24가 됩니다.
• 반대 방향으로도 래핑(wrap around)이 가능합니다.
• 0은 2바이트 부호 없는 정수로 표현 가능하므로 괜찮습니다.
• -1은 표현할 수 없으므로 범위의 맨 끝(최댓값)으로 래핑되어 값 65535를 생성합니다.
• -2는 65534가 됩니다. 이런 식으로 계속됩니다.
부호 없는 숫자에 대한 논란
• 첫째, 부호 있는(signed) 값은 0에서 멀리 떨어진 값들이 범위의 끝에 있기 때문에 실수로 범위의 위나 아래를 넘기기(오버플로우) 쉽지 않습니다.
• 하지만 부호 없는(unsigned) 숫자는 범위의 시작이 0이고, 대다수의 값이 0 근처에 있기 때문에 범위의 하단(bottom)을 넘겨 오버플로우(언더플로우) 시키기가 훨씬 쉽습니다.
• 둘째, 더 교묘하게도, 부호 있는 정수와 부호 없는 정수를 섞어서 사용할 때 예상치 못한 동작이 발생할 수 있습니다.
• C++에서는 수학 연산(예: 산술 또는 비교)에 부호 있는 정수 하나와 부호 없는 정수 하나가 포함된 경우, 부호 있는 정수가 보통 부호 없는 정수로 변환됩니다.
• 따라서 결과도 부호 없는 정수가 됩니다.
베스트 프랙티스 (Best Practice)
• 수량(심지어 음수가 아니어야 하는 수량일지라도)을 저장하거나 수학적 연산을 할 때는 부호 없는 숫자보다 부호 있는 숫자(signed numbers)를 선호하십시오.
• 부호 있는 숫자와 부호 없는 숫자를 섞어서 사용하지 마십시오.
그렇다면 언제 부호 없는 숫자를 사용해야 할까요?
• 첫째, 비트 조작(bit manipulation)을 다룰 때 부호 없는 숫자가 선호됩니다.
• 또한 암호화나 난수 생성 알고리즘처럼 잘 정의된 래핑(wrap-around) 동작이 필요한 경우에도 유용합니다.
• 둘째, 주로 배열 인덱싱(array indexing)과 관련된 경우 부호 없는 숫자의 사용이 불가피할 때가 있습니다.
• 이에 대해서는 배열과 배열 인덱싱 관련 레슨에서 더 자세히 이야기할 것입니다.
• 셋째, 임베디드 시스템(예: 아두이노)이나 프로세서/메모리가 제한된 환경을 위해 개발하는 경우, 성능상의 이유로 부호 없는 숫자의 사용이 더 일반적이고 용인되며(어떤 경우에는 불가피하게) 사용됩니다.
고정 너비 정수 (Fixed-width integers)
• 크기가 고정되어 있기 때문에 이를 고정 너비 정수(fixed-width integers)라고 부릅니다.
• 고정 너비 정수는 <cstdint> 헤더에 다음과 같이 정의되어 있습니다.
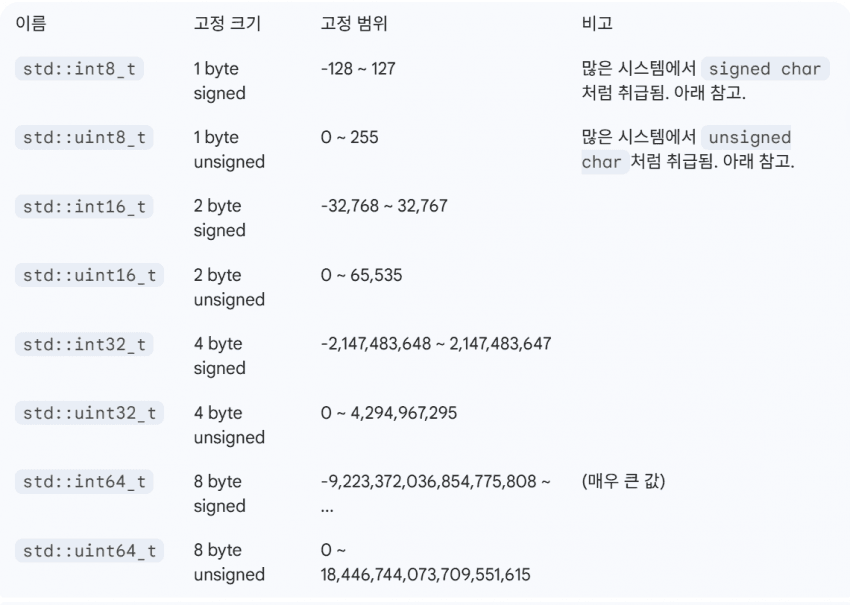
• 고정 너비 정수는 사실 새로운 타입을 정의하는 것이 아닙니다. 원하는 크기를 가진 기존 정수형의 별칭(alias)일 뿐입니다.
빠른(Fast) 및 최소(Least) 정수 타입
• 빠른 타입 (Fast types) (std::int_fast#_t 및 std::uint_fast#_t)
• 적어도 #비트의 크기를 가지면서 가장 빠른 부호 있는/없는 정수 타입을 제공합니다 (# = 8, 16, 32, 64).
• 예를 들어 std::int_fast32_t는 32비트 이상인 정수 중 가장 빠른 타입을 제공합니다. 여기서 '가장 빠르다'는 것은 CPU가 가장 빠르게 처리할 수 있는 정수형을 의미합니다.
• 최소 타입 (Least types) (std::int_least#_t 및 std::uint_least#_t)
• 적어도 #비트의 크기를 가지면서 가장 작은 부호 있는/없는 정수 타입을 제공합니다.
• 예를 들어 std::uint_least32_t는 32비트 이상인 정수 중 가장 작은 타입을 제공합니다.
과학적 표기법(Scientific notation)
• 과학적 표기법은 긴 숫자를 간결하게 작성하기 위한 유용한 약기법입니다.
• 과학적 표기법의 숫자는 다음과 같은 형태를 띱니다.
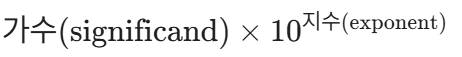
• 관례상 과학적 표기법의 숫자는 소수점 앞에 한 자리 숫자만 오고, 나머지 자릿수는 소수점 뒤에 오도록 작성합니다.
• C++에서는 지수를 입력하거나 표시하기 어렵기 때문에, 우리는 'e' (또는 간혹 'E')라는 문자를 사용하여 "10의 거듭제곱" 부분을 표현합니다.
유효 숫자 (Significant digits)
• 가수(significand, 'e' 앞부분)**에 있는 숫자들을 유효 숫자(significant digits 또는 significant figures)라고 합니다.
• 유효 숫자가 많을수록 숫자는 더 정밀합니다.
십진수를 과학적 표기법으로 변환하는 방법
• 1. 지수(exponent)는 0에서 시작합니다.
• 2. 숫자에 명시적인 소수점이 없다면(예: 123), 암시적으로 오른쪽 끝에 있는 것입니다(예: 123.).
• 3. 소수점 왼쪽에 0이 아닌 숫자가 단 하나만 남을 때까지 소수점을 왼쪽이나 오른쪽으로 이동합니다.
- 소수점을 왼쪽으로 한 칸 이동할 때마다 지수가 1씩 증가합니다.
- 소수점을 오른쪽으로 한 칸 이동할 때마다 지수가 1씩 감소합니다.
• 4. 선행 0(가수의 왼쪽 끝에 있는 0)을 잘라냅니다.
• 5. 원래 숫자에 소수점이 없었던 경우에만 후행 0(가수의 오른쪽 끝에 있는 0)을 잘라냅니다. (우리는 이 0들이 유효하지 않다고 가정합니다. 만약 유효하다는 추가 정보가 있다면 유지할 수 있습니다.)
부동 소수점 수 (Floating point numbers)
• 부동 소수점(Floating point) 타입 변수는 4320.0, -3.33, 0.01226과 같이 소수 부분이 있는 숫자를 저장할 수 있는 변수입니다.
• 부동 소수점 데이터 타입은 항상 부호가 있습니다(signed) (양수와 음수를 모두 저장할 수 있습니다).
부동 소수점 정밀도 (Floating point precision)
• 부동 소수점 타입의 정밀도(precision)는 정보 손실 없이 표현할 수 있는 유효 숫자의 개수를 정의합니다.
• 부동 소수점 타입이 가진 정밀도의 자릿수는 크기(float는 double보다 정밀도가 낮음)와 저장되는 특정 값(어떤 값은 다른 값보다 더 정밀하게 표현될 수 있음)에 따라 달라집니다.
• float는 6~9자리의 정밀도를 가집니다.
• 이는 float가 최대 6자리의 유효 숫자를 가진 어떤 숫자든 정확하게 표현할 수 있음을 의미합니다.
• 7~9자리의 유효 숫자를 가진 숫자는 값에 따라 정확하게 표현될 수도 있고 아닐 수도 있습니다.
• 그리고 9자리 이상의 정밀도를 가진 숫자는 확실히 정확하게 표현되지 않습니다.
• double 값은 15~18자리의 정밀도를 가지며, 대부분의 double 값은 적어도 16자리의 유효 숫자를 가집니다.
• long double은 차지하는 바이트 수에 따라 최소 15, 18 또는 33자리의 유효 숫자를 가집니다.
• 우리는 std::setprecision()이라는 출력 조정자(output manipulator) 함수를 사용하여 std::cout이 보여주는 기본 정밀도를 재설정할 수 있습니다.
• 출력 조정자는 데이터가 출력되는 방식을 변경하며 iomanip 헤더에 정의되어 있습니다.
• 숫자를 정확하게 저장할 수 없어 정밀도가 손실되는 것을 반올림 오차(rounding error)라고 합니다.
불리언 변수 (Boolean variables)
• 불리언 변수는 true(참)와 false(거짓) 두 가지 값만 가질 수 있는 변수입니다.
• 불리언 변수를 선언(declare)하려면 bool 키워드를 사용합니다.
• 정수가 불리언으로 변환될 수 있는 모든 문맥에서, 정수 0은 false로 변환되고, 그 외의 모든 정수는 true로 변환됩니다.
• 불리언 변수의 기본값은 false 입니다.
bool b;
• 불리언 변수를 초기화(initialize)하거나 값을 대입(assign)하려면 true와 false 키워드를 사용합니다.
bool b1 { true };
bool b2 { false };
b1 = false;
bool b3 {}; // 기본값인 false로 초기화됨
• 불리언 값은 실제로는 불리언 변수에 "true"나 "false"라는 단어로 저장되지 않고, 정수값으로 저장됩니다.
• true는 정수 1로, false는 정수 0으로 저장됩니다.
• 불리언은 정수값을 저장하기 때문에 정수형(integral type)으로 간주됩니다.
std::boolalpha를 사용하여 true 또는 false로 출력하기
• 만약 std::cout이 0이나 1 대신 true나 false를 출력하게 하려면 std::boolalpha를 출력하면 됩니다.
• 이것은 아무것도 출력하지 않지만, std::cout이 bool 값을 출력하는 방식을 변경합니다.
예제는 다음과 같습니다:
#include <iostream>
int main()
{
std::cout << true << '\n';
std::cout << false << '\n';
std::cout << std::boolalpha; // bool 값을 true 또는 false로 출력하게 설정
std::cout << true << '\n';
std::cout << false << '\n';
return 0;
}
이 코드는 다음과 같이 출력합니다.
1
0
true
false
• std::noboolalpha를 사용하면 설정을 다시 끌 수 있습니다.
불리언 반환값 (Boolean return values)
• 불리언 값은 어떤 것이 참인지 아닌지 확인하는 함수의 반환값으로 자주 사용됩니다.
• 이러한 함수들은 보통 is (예: isEqual) 또는 has (예: hasCommonDivisor)라는 단어로 시작하는 이름을 가집니다.
문자형 (Chars)
• char 기본 자료형은 단 하나의 문자(character)를 저장하기 위해 설계되었습니다.
• 문자란 글자 한 자, 숫자, 기호, 또는 공백(whitespace) 등이 될 수 있습니다.
• char 데이터 타입은 정수형(integral type)입니다.
• 즉, 내부적으로 값이 정수(integer)로 저장된다는 뜻입니다.
• 불리언(Boolean) 값 0이 false로, 0이 아닌 값이 true로 해석되는 것과 비슷하게, char 변수에 저장된 정수는 ASCII 문자로 해석됩니다.
문자(char) 초기화
• 문자 리터럴을 사용하여 char 변수를 초기화할 수 있습니다.
char ch2{ 'a' }; // 'a'의 코드 포인트로 초기화 (정수 97로 저장됨) (권장함)
• 정수로도 초기화할 수 있지만, 가능하면 피해야 합니다.
char ch1{ 97 }; // 정수 97로 초기화 ('a') (권장하지 않음)
암시적 형 변환 (Implicit type conversion)
• 대부분의 경우, C++은 우리가 기본 자료형(fundamental type)의 값을 다른 기본 자료형으로 변환하는 것을 허용합니다.
• 데이터의 타입을 다른 타입으로 변환하는 과정을 형 변환(type conversion)이라고 합니다.
• 우리가 명시적으로 요청하지 않았는데도 컴파일러가 대신 형 변환을 수행하는 것을 암시적 형 변환(implicit type conversion)이라고 합니다.
형 변환은 새로운 값을 생성합니다 (Type conversion produces a new value)
• 형 변환 과정은 변환할 데이터를 제공하는 값(또는 객체) 자체를 수정하지 않습니다.
• 대신, 변환 과정은 그 데이터를 입력으로 사용하여 변환된 새로운 결과값을 만들어냅니다.
• 변환될 데이터가 인자로 전달되고, 변환된 결과가 (임시 객체에 담겨) 반환되어 호출자가 사용하게 됩니다.
• 어떤 형 변환(예: char에서 int)은 변환되는 값을 항상 보존하지만,
• 어떤 변환(예: double에서 int)은 변환 중에 값이 변경될 수 있습니다.
• 중괄호 초기화(brace initialization)의 경우 에러를 발생시킵니다.
static_cast 연산자를 통한 명시적 형 변환 소개
• 명시적 형 변환은 프로그래머가 컴파일러에게 값을 한 타입에서 다른 타입으로 변환하도록 명시적으로 지시하고, 그 변환 결과에 대해 전적으로 책임을 지겠다고 선언하는 것입니다.
• 명시적 형 변환을 수행하기 위해 대부분의 경우 static_cast 연산자를 사용합니다.
static_cast<새로운_타입>(표현식)
흠 이거나 초6때하던건데
추억 돋겠네
모르는게 많았네. 강좌 써보려고했는데 안쓰길 잘한것같다. 잘봤어요.
자 이제 말해봐